從論文到,一鍵生成!從此報告不用愁!

文 | 子龍
編 | 小軼
俗話說:“行百步者半九十”,論文接受固然可喜可賀,然而這只是萬里長征第一步。一份具有影響力的工作少不了一個后期的宣傳,做好一個PPT絕對是一個技術活。不知道小伙伴們平時怎么做PPT,是復制粘貼長篇大論抑或提綱挈領圖文并茂。直接拷貝論文固然簡單,但是動輒大半頁的文字實在很難讓人提起興趣,大家都明白應該抓住要點,并輔以圖片,但是怎么總結文章各個板塊并且合理排布呢,這又是個難題。
雖然論文千變萬化,但是計算機論文的PPT往往還是比較樸實無華的,往往遵循一定的格式,從介紹到模型,再從實驗到結論,基本上和行文對應,那么對每個板塊抽取核心信息,那么就能生成一份滿意的PPT。
今天介紹一篇'21的文章 D2S: -to- Via - Text 直接省去了苦思PPT細節的麻煩,提出一個基于問答抽取的方法,通過論文內容和給定標題直接生成對應的PPT。下圖就展示了一個用D2S自動生成的論文介紹PPT樣例。上方黑框中的是論文作者自己做的PPT,下面藍框里的是D2S自動生成的。可以看到,文字介紹部分還是十分合理的,與配圖對應,整體排版上還要優于人工制作的PPT。
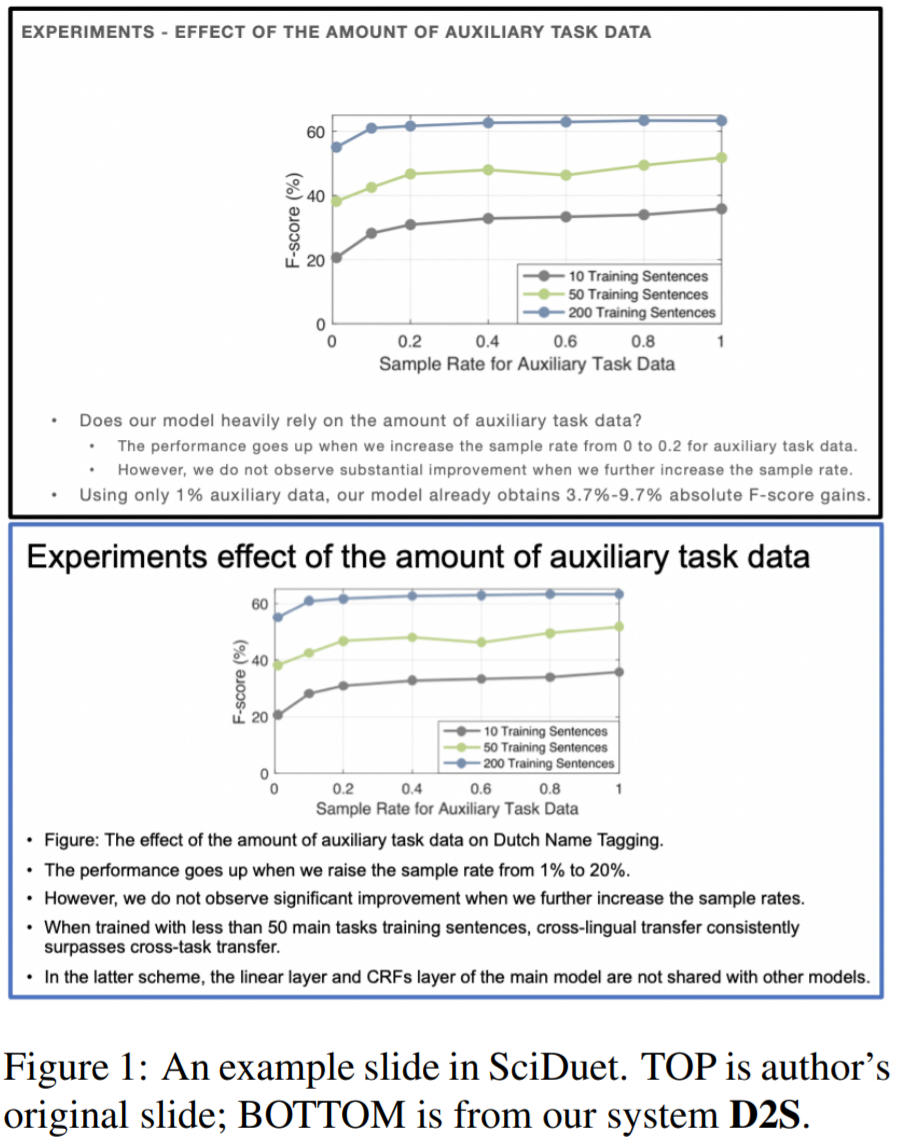
論文題目:
D2S: -to- Via - Text
論文鏈接:
方法
本文將D2S(文檔生成PPT)視為一個封閉領域長文本問答,即限定在計算機論文的領域中,給定論文和每頁PPT的標題,從論文中抽取對應內容并加以總結,作為標題的“答案”。整個模型分為三個模塊,分別是:
關鍵詞模塊
論文的PPT肯定要參考原本論文,從一篇論文的各個版塊的標題那里,可以大致看出一篇文章所關注的要點和行文思路,這些標題可能是最基本的“介紹”、“相關文獻”、“實驗”,也可能是論文所設計的模塊的名稱,比如 is all you need論文中,就有專門介紹的一個部分。這些標題和子標題很自然的就形成了一個樹狀結構(模型圖左下角),這些樹狀結構中的節點被提取出來,作為關鍵詞,輔助后續的內容生成。
信息抽取模塊
關鍵詞模塊只是為了后續工作提供了一定的幫助,而信息抽取模塊才真正開始處理論文和PPT標題。本文采用了基于 BERT[1]的信息抽取模型。信息抽取模型可以根據相關程度在若干候選中給出一個排序,這個模塊就是為了從論文中找到和對應PPT標題相關的片段。
訓練模型
既然需要模型學習相關性,最容易想到的方法就是通過人工標注進行有監督學習,然而很難從最終完成的PPT中看出當前頁面與論文中哪些地方相關,于是本文選擇了一個折中的方法來訓練信息抽取模型,它將當前PPT頁面中的內容作為正例,將其他PPT頁面中的內容作為反例,訓練模型辨別這兩者的區別,進而學習PPT標題和內容的相關性,所學習得到的相關性可以后續用于評估PPT標題和論文片段的相關性。
抽取片段
因為PPT頁面中的內容和論文片段十分相似,于是通過上述方法訓練的模型可以很好的運用于評估PPT標題和論文片段的相關性。同時,每個論文片段同時又擁有對應的標題或者子標題,即關鍵詞模塊提取到的關鍵詞,最終每個論文片段與當前PPT標題的相關性取決于兩方面:
其中、、分別為PPT標題、論文片段、片段對應關鍵詞的文本特征。
問答模塊
最終每頁PPT中的內容由問答模塊來生成,這里采用的是預訓練的BART模型[2]。我們需要將“問題”和“上下文信息”提供給問答模型,這里的“問題”即每頁PPT的標題,上下文信息分為兩方面:
其中a,b為兩個字符串,d為兩者的編輯距離。
將整合好的“問題”和“上下文”以如下格式輸入到預訓練的BART,得到對應PPT的內容:
圖表抽取模塊
沒有插圖的PPT是不完整的,D2S對圖片的處理非常簡單,直接利用信息抽取模塊中訓練得到的模型評估PPT標題和圖片或者表格的描述文字計算相關性,進而插入到對應PPT頁面內。
模型表現
本文主要評估生成PPT的兩個方面:
PPT內容生成效果
因為這個任務的本質是信息抽取與總結,本文對比了D2S的問答模塊(記為)與如下:、(本文模型去除部分)。
同時,本文還將信息抽取模塊中的混合的方法(-Mix IR)和傳統的基于離散單詞對應的BM25( IR)做對比。結果如下:
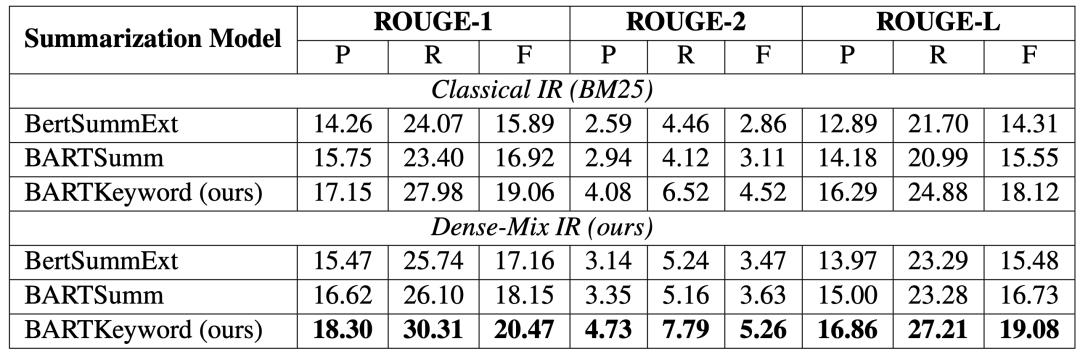
從結果中可以看到結合關鍵詞的方法往往能夠得到更好的效果。在信息抽取階段引入關鍵詞,可以更好地評估PPT標題和論文片段的相關性,進而得到更加準確的上下文,這一點從各個的結果中都可以看出。在問答模塊階段,與以往單純將論文片段作為上下文,D2S中的將關鍵詞同樣輸入到上下文部分,也大大地提高了值。
可見,論文中的標題和子標題是一篇文章的骨架,很大程度上可以幫助針對論文內容的總結歸納工作,進而在生成PPT的任務中大有作為。
總結
本文由諸多模塊組成,利用了信息抽取和問答模型對計算機領域的論文進行總結,并創造性的提出了生成PPT這樣的任務,同時利用了論文各個版塊的標題和子標題提供更多的信息。




